


 400-139-9200
400-139-9200


如何使用 INFINI 迁移功能 #
简介 #
本文将介绍如何使用 INFINI Console 和 INFINI Gateway 来迁移 Elasticsearch 索引数据。
准备 #
- 下载并安装最新版 INFINI Console (版本要求 0.9.0-1036 及以上)
- 下载并安装最新版的 INFINI Gateway (版本要求 1.12.0-915 及以上)
- 两个 Elasticsearch 集群
Gateway 迁移配置 #
下载解压之后默认配置文件名为 gateway.yml,内容如下:
#the env section used for setup default settings,it can be overwritten by system environments.
#eg: PROD_ES_ENDPOINT=http://192.168.3.185:9200 LOGGING_ES_ENDPOINT=http://192.168.3.185:9201 ./bin/gateway
env: #use $[[env.LOGGING_ES_ENDPOINT]] in config instead
LOGGING_ES_ENDPOINT: https://localhost:9200
LOGGING_ES_USER: admin
LOGGING_ES_PASS: admin
PROD_ES_ENDPOINT: https://localhost:9200
PROD_ES_USER: admin
PROD_ES_PASS: admin
GW_BINDING: "0.0.0.0:8000"
API_BINDING: "0.0.0.0:2900"
# omitted configurations
# ...
一般我们只要按需修改 Elasticsearch 集群的地址和身份验证信息, 这里我们修改 env 配置节如下:
env: #use $[[env.LOGGING_ES_ENDPOINT]] in config instead
LOGGING_ES_ENDPOINT: https://192.168.3.12:9212
LOGGING_ES_USER: admin
LOGGING_ES_PASS: admin
PROD_ES_ENDPOINT: https://192.168.3.12:9212
PROD_ES_USER: admin
PROD_ES_PASS: admin
GW_BINDING: "0.0.0.0:8000"
API_BINDING: "0.0.0.0:2900"
这里需要注意的是 LOGGING_ES_ENDPOINT 配置的是日志写入的 ES 集群,这个集群需要和 Console 配置的系统 ES 集群保持一致
启动 Gateway #
./gateway-xxx-xxx -config gateway.yml
注册 Gateway #
这里我们使用极限网关作为迁移任务的执行者,需要提前将网关实例注册到 Console 里面管理,后面创建迁移任务的时候会用到。
点击 INFINI Console 中左侧菜单 资源管理 > 网关管理,然后点击 新建 按钮注册新的实例,如下图所示:

输入网关的地址,这里要注意网关的默认 API 地址使用的是 2900 端口,这里我们输入 192.168.3.12:2900,然后点击下一步

点击下一步,完成网关注册
注册源集群和目标集群 #
点击 INFINI Console 中左侧菜单 资源管理 > 集群管理,然后点击注册集群,先后注册源集群 es-v5616 和目标集群 es-v710,如下图所示:

如果 Elasticsearch 集群有身份验证,需要设置身份验证信息,然后点击下一步

确认集群信息无误,然后点击下一步

到这里源目标集群就注册完成了,目标集群 es-v710 的注册步骤也是一样的,这里就不赘述了。
创建迁移任务 #
点击 INFINI Console 中左侧菜单 数据工具 > 数据迁移,然后点击新建按钮创建迁移任务,如下图所示:
配置迁移集群 #

在源集群列表中选择集群 es-v5616,在目标集群列表中选择集群 es-v710
配置迁移索引 #
点击选择迁移索引按钮,如下图:

这里我们选择了索引 test ,然后点击确认

test 索引包含两个 type,系统自动按 type 拆分成两个索引
表格右方可以设置目标索引名称和文档 type,按需修改即可。 选择完索引之后,点击下一步,进行索引的初始化操作,如下图:

点击展开后,可以看到有 mappings 和 settings 设置,如图所示,
mappings 设置左侧显示的是源集群索引的 mappings, 可以点击中间按钮复制到右侧,
然后点击 Auto Optimize 自动优化(兼容性优化)。设置完成后点击 Start
执行初始化 mappings 和 settings 操作,若没有设置,则自动跳过。
如果已通过其他方式初始化索引 settings 和 mappings, 这里可以直接点击下一步跳过
完成索引初始化之后,点击下一步,进行迁移任务的数据范围设置和分区设置,如下图:
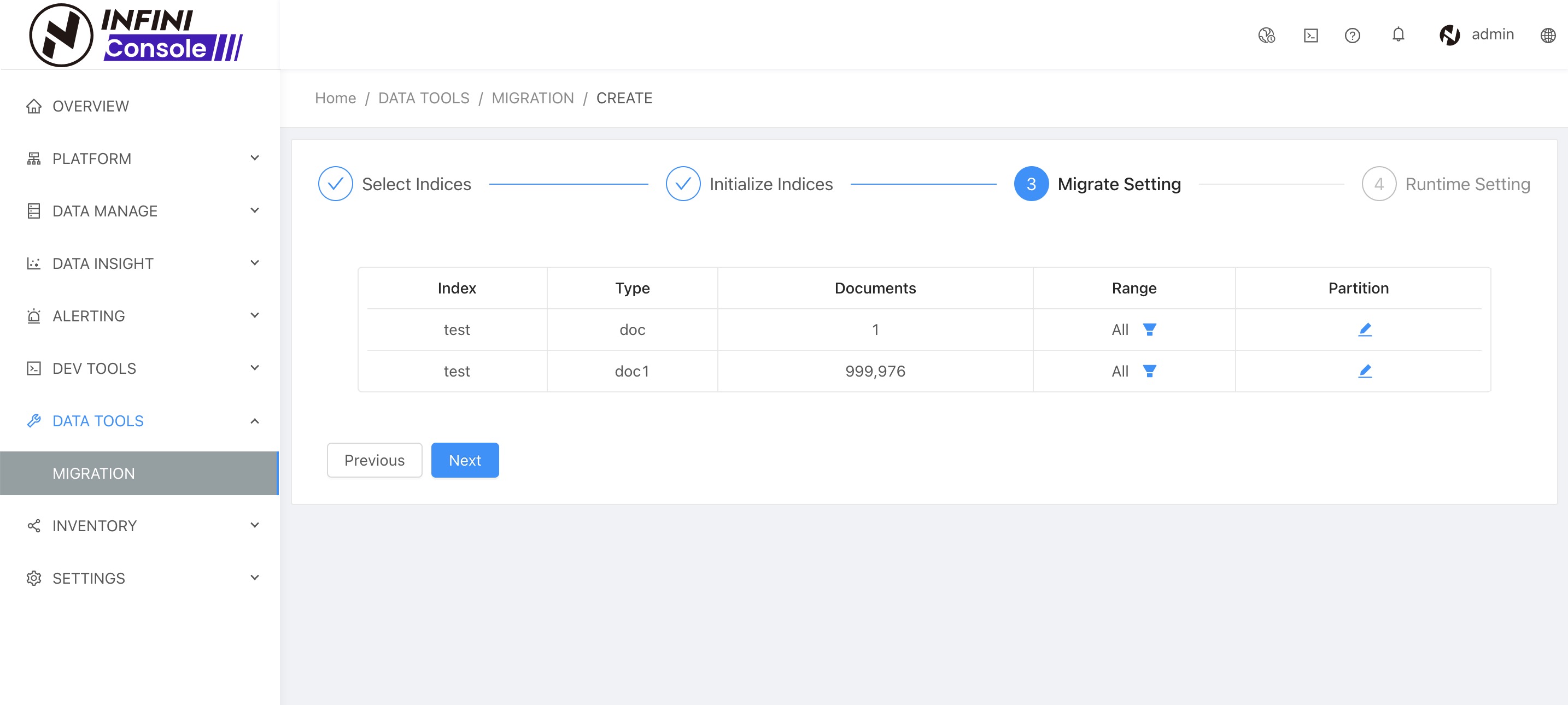
配置数据范围 #
如果需要过滤数据迁移,可以进行数据范围的设置,这里我们进行全量的数据迁移,就不设置了
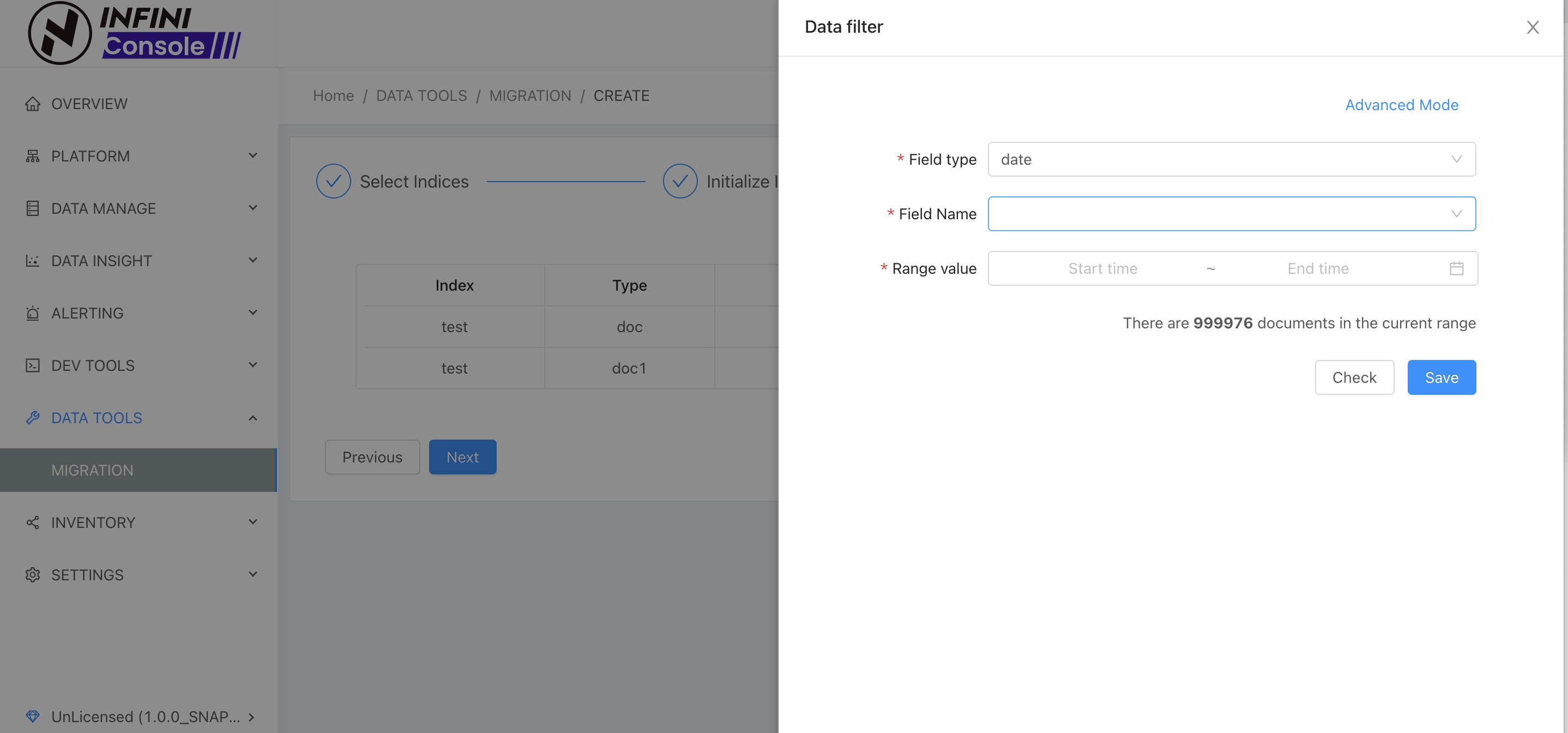
配置数据分区 #
如果一个索引数据量特别大,可以进行数据分区的设置。数据分区根据设置的字段,以及分区步长将数据拆成多段,系统最终会将一个分段的数据作为一个子任务去运行,迁移数据, 这样的话即使,一个分段迁移过程出现异常,只需要重跑这个子任务。
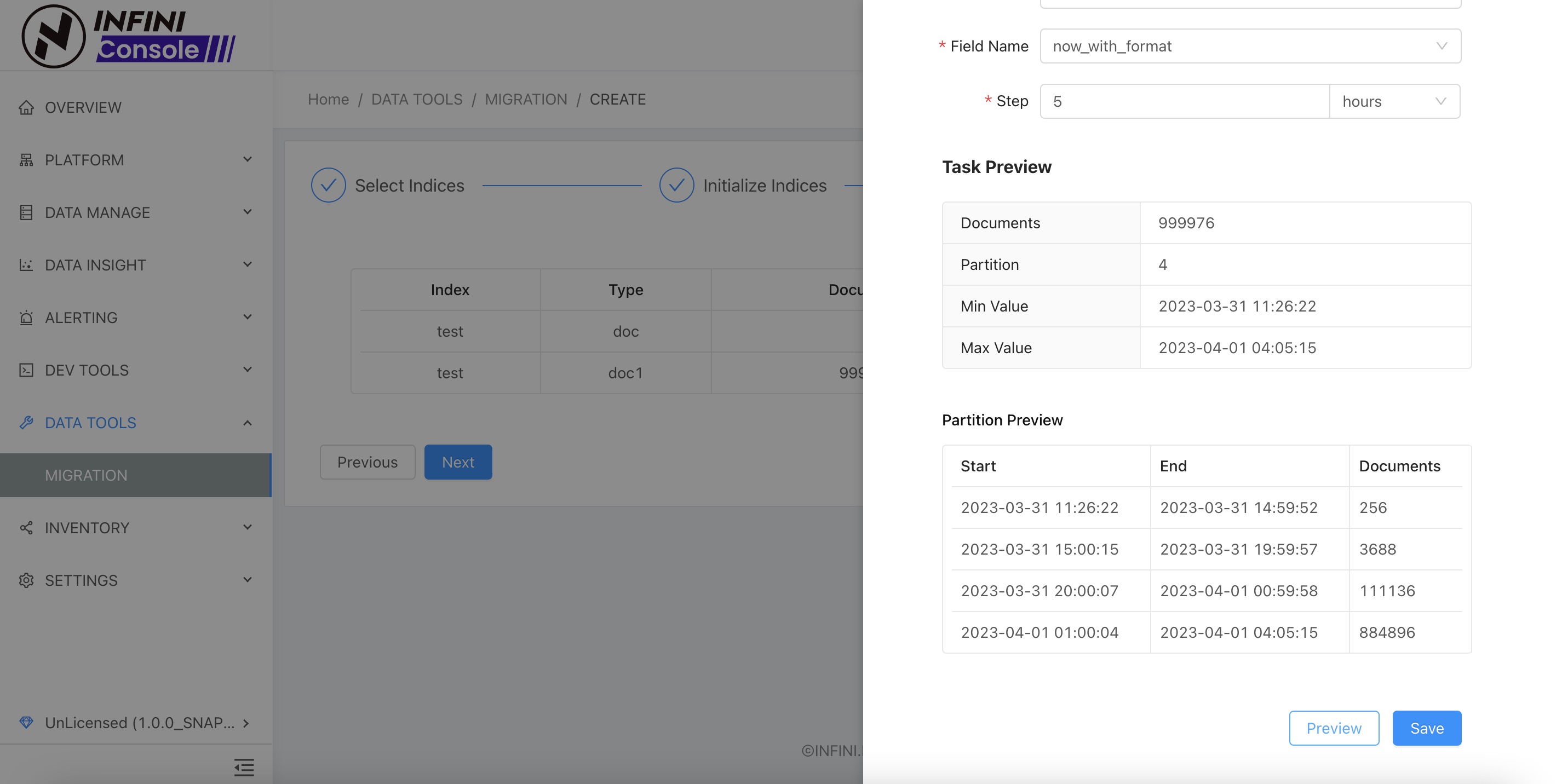
数据分区设置目前支持按照日期类型字段(date),和数字类型 (number) 拆分分区,如上图所示,我们选择日期类型字段 now_widh_format 进行拆分分区,分区步长设置为 5 分钟(5m),然后点击预览按钮,可以看到根据设置拆分可以得到 8 个分区(文档数为 0 的分区最终不会生成子任务)。 根据预览信息确认分区设置无误之后,点击保存关闭分区设置并保存,然后点击下一步进行运行设置。
运行设置 #

一般情况下使用默认设置,然后执行节点选择先前注册的网关实例 Nebula,然后点击创建任务。
启动迁移任务 #
创建迁移任务成功后会看到任务列表,如下图:

可以看到,最近一条任务就是我们刚创建的,然后在表格右侧操作栏中点击 start 开始任务
任务开始之前,需要确认如果迁移索引涉及到 ILM 配置,需要确认目标集群中相关索引模版,ILM 别名是否配置好。
点击开始按钮 启动迁移任务。
查看迁移任务进度 #
任务启动成功之,点击详情进入任务详情页查看任务执行状态。点击 Refresh 按钮开启自动刷新之后,我们可以看到任务详情有如下变化:
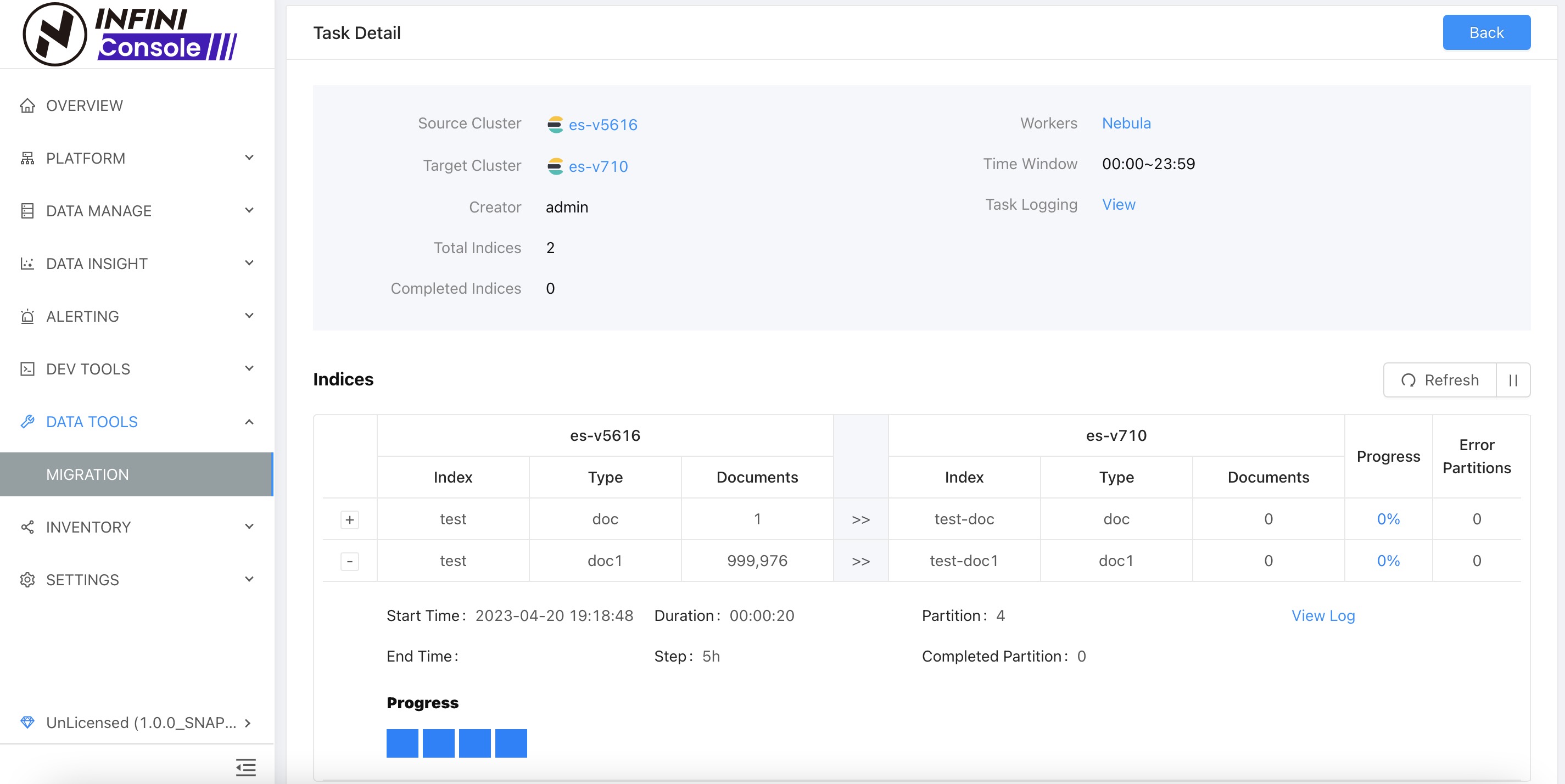
图中蓝色方块表示,子任务(分区任务)已经在运行,灰色表示任务还没有开始
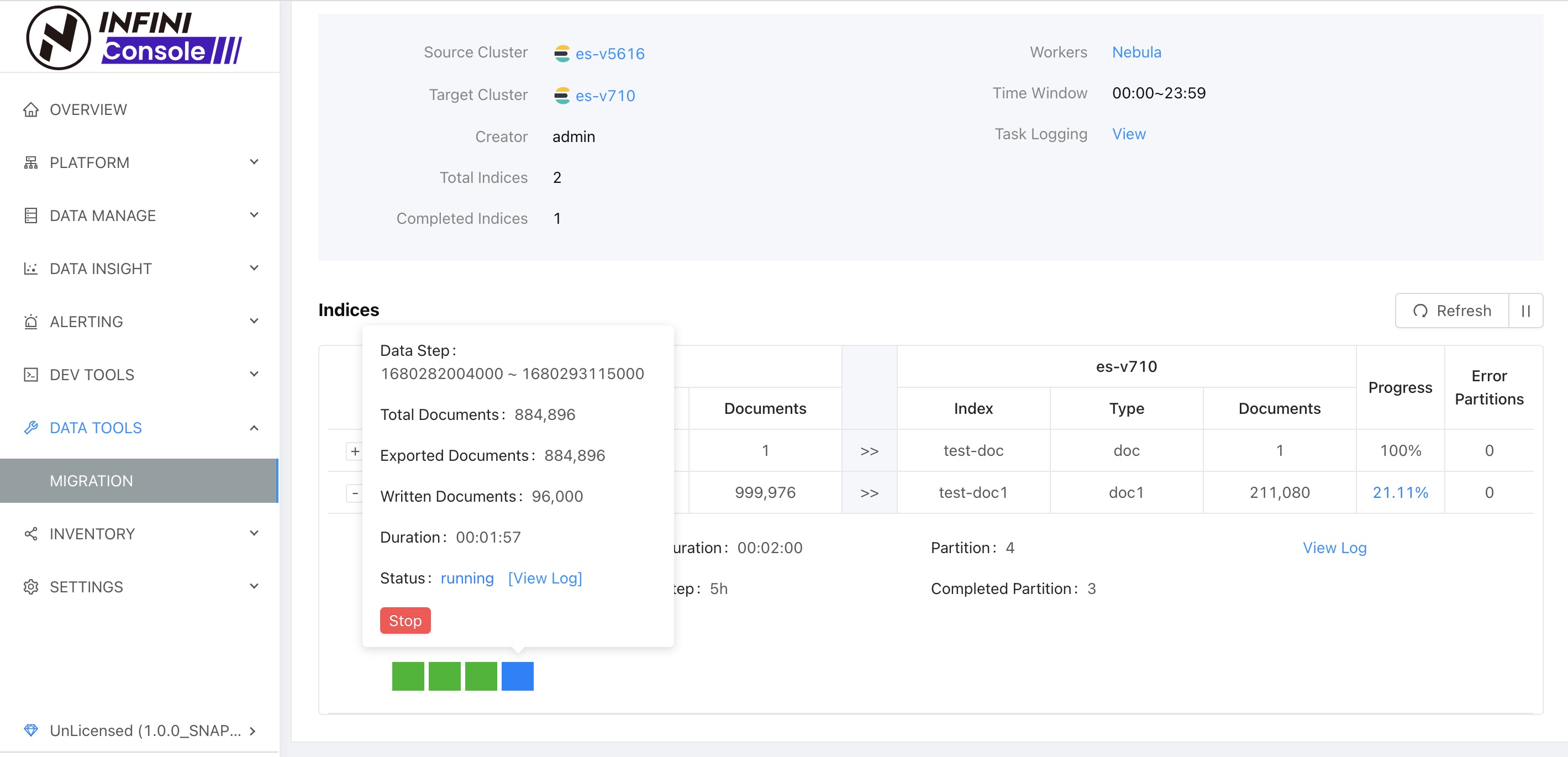
上图中可以看到方块变成了绿色,表示子任务(分区任务)已经数据迁移完成,索引 test-doc 的迁移进度是 100%,索引 test-doc1 迁移进度是 21.11
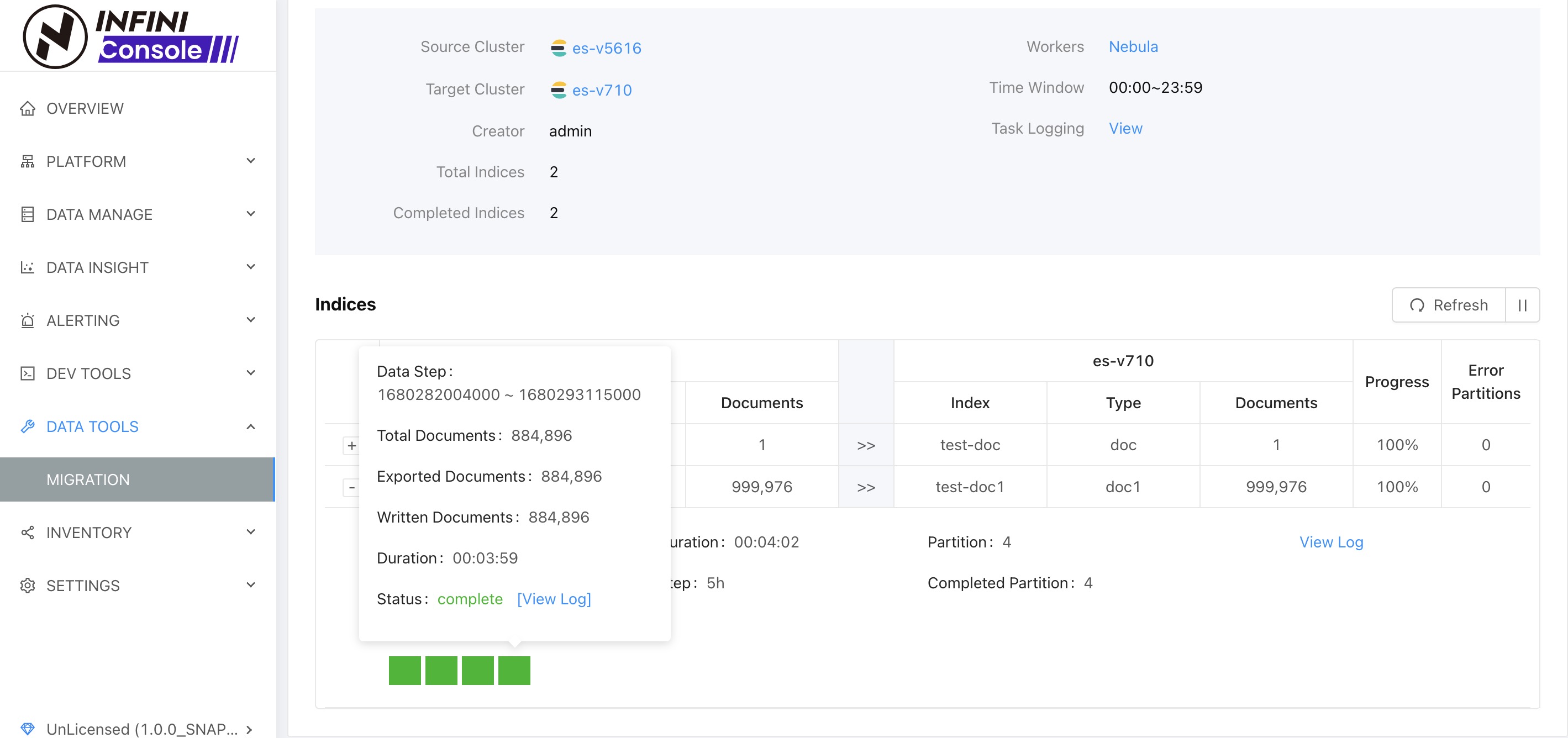
上图中可以看到所有方块变成了绿色,索引迁移进度都是 100%,表示数据已经迁移完成。
如果迁移过程中有方块变成了红色,则表示迁移过程出现了错误,这时候可以点击任务方块进度信息里面的 View Log 查看错误日志,定位具体错误原因。
小结 #
使用 INFINI 数据迁移功能可以很方便地将 Elasticsearch 数据进行跨版本迁移,并且可以很直观地查看当前数据的迁移进度。







