


 400-139-9200
400-139-9200


基础查询 #
介绍 #
SQL 中的 SELECT 语句是从 Easysearch 索引中检索数据的最常见查询。在本文档中,只涵盖涉及单个索引和查询的简单 SELECT 语句。 SELECT 语句包括 SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY 和 LIMIT 子句。其中,SELECT 和 FROM 是指定要获取哪些字段以及它们应该从哪个索引获取的基础。 其它所有子句都是可选的,根据您的需求使用。请继续阅读以了解它们的详细描述、语法和用例。
语法 #
SELECT 语句的语法如下:
SELECT [ALL | DISTINCT] (* | expression) [[AS] alias] [, ...]
FROM index_name
[WHERE predicates]
[GROUP BY expression [, ...]
[HAVING predicates]]
[ORDER BY expression [ASC | DESC] [NULLS {FIRST | LAST}] [, ...]]
[LIMIT [offset, ] size]
尽管不支持批量执行多个查询语句,但仍然允许以分号 ; 结束。例如,你可以运行 SELECT * FROM accounts; 而不会遇到问题。这对于支持其他工具生成的查询,如 Microsoft Excel 或 BI 工具,非常有用。
基本原理 #
除了 SQL 语言的预定义关键字外,最基本的元素是字面量和标识符。字面量是数字、字符串、日期或布尔常量。 标识符表示 Easysearch 的索引或字段名称。通过应用算术运算符和 SQL 函数,基本的字面量和标识符可以构建成复杂的表达式。
表达式原子 (expressionAtom) :

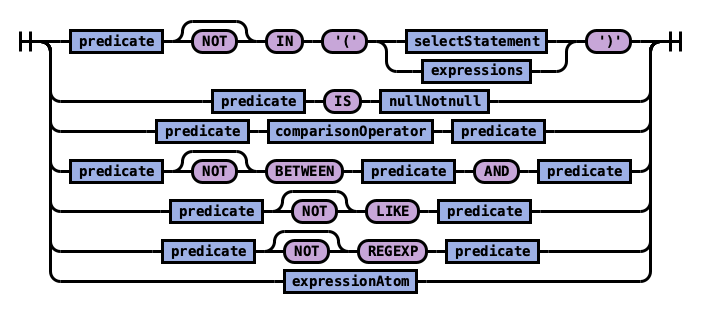
表达式可以通过逻辑运算符组合成谓词。通常,谓词用于 WHERE 和 HAVING 子句中,根据指定的条件过滤数据。
表达式 (expression) :

谓词 (predicate) :
执行顺序 #
实际的执行顺序与语句的顺序大不相同:
FROM index
WHERE predicates
GROUP BY expressions
HAVING predicates
SELECT expressions
ORDER BY expressions
LIMIT size
SELECT #
SELECT 子句指定应检索 Easysearch 索引中的哪些字段。
语法 #
selectElements:

示例 1:查询所有字段 #
您可以用来获取索引中的所有字段,这在您只想快速查看数据时非常方便。*
SQL query:
POST /_sql
{
"query" : "SELECT * FROM accounts"
}
解释:
{
"from" : 0,
"size" : 200
}
结果集:
| Account Number | First Name | Gender | City | Balance | Employer | State | Address | Last Name | Age | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Amber | M | Brogan | 39225 | Pyrami | IL | amberduke@pyrami.com | 880 Holmes Lane | Duke | 32 |
| 6 | Hattie | M | Dante | 5686 | Netagy | TN | hattiebond@netagy.com | 671 Bristol Street | Bond | 36 |
| 13 | Nanette | F | Nogal | 32838 | Quility | VA | nanettebates@quility.com | 789 Madison Street | Bates | 28 |
| 18 | Dale | M | Orick | 4180 | null | MD | daleadams@boink.com | 467 Hutchinson Court | Adams | 33 |
示例 2:查询特定字段 #
通常情况下,您会在子句中指定特定的字段名,以避免检索到大量不必要的数据。SELECT
SQL query:
POST /_sql
{
"query" : "SELECT firstname, lastname FROM accounts"
}
解释:
{
"from" : 0,
"size" : 200,
"_source" : {
"includes" : [
"firstname",
"lastname"
],
"excludes" : [ ]
}
}
结果集:
| firstname | lastname |
|---|---|
| Amber | Duke |
| Dale | Adams |
| Hattie | Bond |
| Nanette | Bates |
示例 3:使用字段别名 #
别名通常用于通过缩短字段名称来提高查询的可读性。
SQL query:
POST /_sql
{
"query" : "SELECT account_number AS num FROM accounts"
}
解释:
{
"from" : 0,
"size" : 200,
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
}
}
结果集:
| num |
|---|
| 1 |
| 6 |
| 13 |
| 18 |
示例4:查询去重字段 #
默认情况下,SELECT ALL 生效以返回所有行。当您想要去重并获取唯一字段值时,DISTINCT 很有用。您可以提供一个或多个字段名(目前不支持 DISTINCT *)。
SQL query:
POST /_sql
{
"query" : "SELECT DISTINCT age FROM accounts"
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"age"
],
"excludes" : [ ]
},
"stored_fields" : "age",
"aggregations" : {
"age" : {
"terms" : {
"field" : "age",
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
}
}
}
}
结果集:
| age |
|---|
| 28 |
| 32 |
| 33 |
| 36 |
实际上,您可以在一个子句中使用任何表达式,例如:DISTINCT 。
os> SELECT DISTINCT SUBSTRING(lastname, 1, 1) FROM accounts;
fetched rows / total rows = 3/3
+-----------------------------+
| SUBSTRING(lastname, 1, 1) |
|-----------------------------|
| A |
| B |
| D |
+-----------------------------+
FROM #
FROM 子句指定 Easysearch 索引,从中检索数据。在上一节中,您已经了解了如何在 FROM 子句中指定单个索引。这里我们提供更多用例示例。
在 FROM 子句中支持子查询。有关更多详细信息,请查看文档。
语法 #
tableName:
示例1:使用索引别名 #
可以在 FROM 子句中给索引一个别名,并在查询的多个子句中使用它。
SQL query:
POST /_sql
{
"query" : "SELECT acc.account_number FROM accounts acc"
}
示例 2:按索引模式从多个索引中进行选择 #
或者,您可以通过索引模式从多个名称相似的索引中进行查询。这对于 Logstash 索引模板创建的以日期为后缀的索引来说非常方便。
SQL query::
POST /_sql
{
"query" : "SELECT account_number FROM account*"
}
WHERE #
WHERE 子句指定应受影响的 Easysearch 文档应符合的条件。它由使用 =, <>, >, >=, <, <=, IN, BETWEEN, LIKE, IS NULL 或 IS NOT NULL 的谓词组成。这些谓词可以通过逻辑运算符 NOT、AND 或 OR 结合起来,构建更复杂的表达式。
对于 LIKE 和其他全文搜索主题,请参阅全文搜索文档。
除了 SQL 查询,WHERE 子句也可以用于 SQL 语句,例如 DELETE。有关详细信息,请参阅数据操作语言文档。
示例 1:比较运算符 #
基本比较运算符,例如 =, <>, >, >=, <, <=,可以用于数字、字符串或日期。 IN 和 BETWEEN 对于多个值或范围的比较非常方便。
SQL query:
POST /_sql
{
"query" : """
SELECT account_number
FROM accounts
WHERE account_number = 1
"""
}
解释:
{
"from" : 0,
"size" : 200,
"query" : {
"bool" : {
"filter" : [
{
"bool" : {
"must" : [
{
"term" : {
"account_number" : {
"value" : 1,
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
},
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
}
}
结果集:
| account_number |
|---|
| 1 |
示例2:缺失的字段 #
Easysearch 允许灵活的模式,索引中的文档可能具有不同的字段。在这种情况下,您可以使用 IS NULL 或 IS NOT NULL 来检索缺失的字段或仅存在的字段。
注意,目前我们不明确区分缺失字段和设置为 NULL 的字段。
SQL query:
POST /_sql
{
"query" : """
SELECT account_number, employer
FROM accounts
WHERE employer IS NULL
"""
}
解释:
{
"from" : 0,
"size" : 200,
"query" : {
"bool" : {
"filter" : [
{
"bool" : {
"must" : [
{
"bool" : {
"must_not" : [
{
"exists" : {
"field" : "employer.keyword",
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
},
"_source" : {
"includes" : [
"account_number",
"employer"
],
"excludes" : [ ]
}
}
结果集:
| account_number | employer |
|---|---|
| 18 | null |
GROUP BY #
GROUP BY 将具有相同字段值的文档分组到桶中。它通常与聚合函数一起使用,在每个桶内聚合。有关更多详细信息,请参阅 SQL 函数文档。
请注意,WHERE 子句在 GROUP BY 子句之前应用。
示例 1:按字段分组 #
SQL query:
POST /_sql
{
"query" : """
SELECT age
FROM accounts
GROUP BY age
"""
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"age"
],
"excludes" : [ ]
},
"stored_fields" : "age",
"aggregations" : {
"age" : {
"terms" : {
"field" : "age",
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
}
}
}
}
结果集:
| age |
|---|
| 28 |
| 32 |
| 33 |
| 36 |
示例 2:按字段别名分组 #
字段别名可在 GROUP BY 子句中访问。
SQL query:
POST /_sql
{
"query" : """
SELECT account_number AS num
FROM accounts
GROUP BY num
"""
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
},
"stored_fields" : "account_number",
"aggregations" : {
"num" : {
"terms" : {
"field" : "account_number",
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
}
}
}
}
结果集:
| num |
|---|
| 1 |
| 6 |
| 13 |
| 18 |
示例 3:按序号分组 #
或者,SELECT 子句中的字段序号也可以用于分组。然而,这并不推荐,因为您的 GROUP BY 子句依赖于 SELECT 子句中的字段,并需要相应更改。
SQL query:
POST /_sql
{
"query" : """
SELECT age
FROM accounts
GROUP BY 1
"""
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"age"
],
"excludes" : [ ]
},
"stored_fields" : "age",
"aggregations" : {
"age" : {
"terms" : {
"field" : "age",
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
}
}
}
}
结果集:
| age |
|---|
| 28 |
| 32 |
| 33 |
| 36 |
示例 4:按标量函数分组 #
标量函数可以在 GROUP BY 子句中使用,并且必须在 SELECT 子句中出现。
SQL query:
POST /_sql
{
"query" : """
SELECT ABS(age) AS a
FROM accounts
GROUP BY ABS(age)
"""
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"script"
],
"excludes" : [ ]
},
"stored_fields" : "abs(age)",
"script_fields" : {
"abs(age)" : {
"script" : {
"source" : "def abs_1 = Math.abs(doc['age'].value);return abs_1;",
"lang" : "painless"
},
"ignore_failure" : false
}
},
"aggregations" : {
"abs(age)" : {
"terms" : {
"script" : {
"source" : "def abs_1 = Math.abs(doc['age'].value);return abs_1;",
"lang" : "painless"
},
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
}
}
}
}
结果集:
| a |
|---|
| 28.0 |
| 32.0 |
| 33.0 |
| 36.0 |
HAVING #
HAVING 子句通过谓词过滤 GROUP BY 子句的结果。因此,聚合函数,甚至与 SELECT 子句中不同的聚合函数,也可以在谓词中使用。
示例 #
SQL query:
POST /_sql
{
"query" : """
SELECT age, MAX(balance)
FROM accounts
GROUP BY age
HAVING MIN(balance) > 10000
"""
}
解释:
{
"from" : 0,
"size" : 0,
"_source" : {
"includes" : [
"age",
"MAX"
],
"excludes" : [ ]
},
"stored_fields" : "age",
"aggregations" : {
"age" : {
"terms" : {
"field" : "age",
"size" : 200,
"min_doc_count" : 1,
"shard_min_doc_count" : 0,
"show_term_doc_count_error" : false,
"order" : [
{
"_count" : "desc"
},
{
"_key" : "asc"
}
]
},
"aggregations" : {
"MAX_0" : {
"max" : {
"field" : "balance"
}
},
"min_0" : {
"min" : {
"field" : "balance"
}
},
"bucket_filter" : {
"bucket_selector" : {
"buckets_path" : {
"min_0" : "min_0",
"MAX_0" : "MAX_0"
},
"script" : {
"source" : "params.min_0 > 10000",
"lang" : "painless"
},
"gap_policy" : "skip"
}
}
}
}
}
}
结果集:
| age | MAX(balance) |
|---|---|
| 28 | 32838 |
| 32 | 39225 |
ORDER BY #
ORDER BY 子句指定用于对结果进行排序的字段以及排序方向。
示例 1:按字段排序 #
除了常规字段名称外,序号、别名或标量函数也可以像在 GROUP BY 中一样使用。可以附加 ASC(默认)或 DESC 表示按升序或降序排序。
SQL query:
POST /_sql
{
"query" : "SELECT account_number FROM accounts ORDER BY account_number DESC"
}
解释:
{
"from" : 0,
"size" : 200,
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
},
"sort" : [
{
"account_number" : {
"order" : "desc"
}
}
]
}
结果集:
| account_number |
|---|
| 18 |
| 13 |
| 6 |
| 1 |
示例 2:按聚合函数排序
聚合函数可以在 ORDER BY 子句中使用。您可以通过相同的函数调用、别名或在选择列表中的序号来引用它:
os> SELECT gender, MAX(age) FROM accounts GROUP BY gender ORDER BY MAX(age) DESC;
fetched rows / total rows = 2/2
+----------+------------+
| gender | MAX(age) |
|----------+------------|
| M | 36 |
| F | 28 |
+----------+------------+
即使在 SELECT 子句中不存在,它也可以按照以下方式使用:
os> SELECT gender, MIN(age) FROM accounts GROUP BY gender ORDER BY MAX(age) DESC;
fetched rows / total rows = 2/2
+----------+------------+
| gender | MIN(age) |
|----------+------------|
| M | 32 |
| F | 28 |
+----------+------------+
LIMIT #
为了防止将大量数据拉取到内存中,需要指定返回的文档数量上限。这种情况下,LIMIT 子句非常有用。 基本上,限制是设置在查询规划中的,所以不同的 LIMIT 和 OFFSET 可能会在结果中导致不可预测的子集。因此,建议在带有 limit 关键字的查询中使用 order by,以强制结果集中的固定排序。
示例 1:限制结果大小 #
给定一个正数,LIMIT 将使用它作为页面大小,最多获取指定大小的结果。
SQL query:
POST /_sql
{
"query" : """
SELECT account_number
FROM accounts
ORDER BY account_number LIMIT 1
"""
}
解释:
{
"from" : 0,
"size" : 1,
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
},
"sort" : [
{
"account_number" : {
"order" : "asc"
}
}
]
}
结果集:
| account_number |
|---|
| 1 |
示例2:按偏移量获取结果 #
偏移位置可以作为第一个参数给出,以指示从何处开始获取。虽然在大型索引上效率低下,但这可以用作简单的分页解决方案。
通常在这种情况下需要使用 ORDER BY,以确保页面之间具有相同的顺序。
SQL query:
POST /_sql
{
"query" : """
SELECT account_number
FROM accounts
ORDER BY account_number LIMIT 1, 1
"""
}
解释:
{
"from" : 1,
"size" : 1,
"_source" : {
"includes" : [
"account_number"
],
"excludes" : [ ]
},
"sort" : [
{
"account_number" : {
"order" : "asc"
}
}
]
}
结果集:
| account_number |
|---|
| 1 |
偏移位置也可以在 OFFSET 关键字后面给出,以下是一个示例:
>os SELECT age FROM accounts ORDER BY age LIMIT 2 OFFSET 1
fetched rows / total rows = 2/2
+-------+
| age |
|-------|
| 32 |
| 33 |
+-------+







